
The Segmentation Problem
A journey to replicating Apple's image lifting feature
The problem.
As a seller publishes more products on their store, they might want to change the background of product images to maintain a consistency throughout their store. During festive events and seasons, updating the images to match also helps in keeping the store relevant. However, background removal is a non-trivial task that requires specialized software and repeating the process for many products become tedious very quickly.
The goal.
Here at Konigle, I'm trying to create a service that can abstract out the process of background replacement, so that it can be easily applied to products across a store. There are a few requirements to keep in mind:
- The service should produce results that are mostly acceptable most of the time. This means that the images generated should be usable as product images without further input from the seller, with a reasonably small margin of error that can be easily fixed by the seller. The seller should not be expected to provide editorial input to every image that needs to be updated, as it defeats the purpose of automating the background replacement process.
- The service should be reasonably fast. With stores easily going beyond 50 products, the seller should not have to wait more than a minute for each image to be processed.
Act 1. Segmentation.
Given the description of such as service, it's easy to draw comparisons with the image lifting feature that Apple introduced in 2022. The feature is implemented on device and separates the image subject from the background almost instantaneously when you long press the image, which lends some confidence that I could achieve a similar result that takes slightly longer and performs slightly worse, but is still acceptable by most sellers.
First, a quick search reveals three segmentation tasks to choose from:
- Semantic segmentation. This segments the image into parts that belong to the same class.
- Instance segmentation. This segments the image into individual objects.
- Panoptic segmentation. This segments the image by combining the strategies of the first two tasks to produce both class and object labels.
Since background removal only requires separating the subject from the rest of the image, it does not need the finer labeling of instance and panoptic segmentation. After some experimenting with various models, I chose "shi-labs/oneformer_coco_swin_large" as the segmentation model as it produces great results with semantic segmentation.

As seen in the images above, both shoes are labelled as the same shade as they belong to the same class, whereas the wooden floor as the background is a different class.
However, an issue with segmentation is that the labels have no unambiguous indication that it is the main subject of the image, especially when the image is cluttered with many layers of objects. This information is only known by the seller, hence a solution would be to return every label for the seller to choose from. However, this goes against the requirement of hands-off automation, so we are left to predict what the seller probably wants.


Act 2. Guessing the subject.
Despite not knowing which layers of objects are of importance, there are some things we can infer from product images in general.
- The product is usually near the center of the image and take up much of the space, thus we can focus on the center section when looking for labels of interest.
- The background is generally clean to direct attention towards the product.
Hence, the first approach I tried was to incrementally include labels until the resulting mask covers a certain percentage of the image's area. However, it was difficult trying to determine where this threshold is, as it would include the background label if the image subject was too small. In addition, if the resulting image was undesirable, it is undesirable for the seller to specify this threshold.
A potentially simpler approach is to restrict the search portion to a square slightly smaller than the image and centered, and include any labels that are mostly within the search area. However, I chanced upon a more interesting method that I wanted to explore.
This method came in the form of the "CIDAS/clipseg-rd64-refined" model that I came across while browsing Hugging Face's list of models. It was attractive because it can generate segmentations based on text and visual prompts, thus it became possible to describe the subject to be extracted. This opened the possibility of two workflows:
- If the particular resulting image with its background replaced was wrongly segmented, the seller could use a few words to describe the image subject for a better segmentation.
- Dynamic text prompting could also be built into the background removal process by extracting a description of the product from the existing product title.

However, the CLIPSeg model does not segment the image as cleanly as the OneFormer one does, thus the two models have to be combined to produce a desirable mask. In my implementation, I used CLIPSeg's output to choose the corresponding labels that it covers in OneFormer's segmentation map, creating the following result.



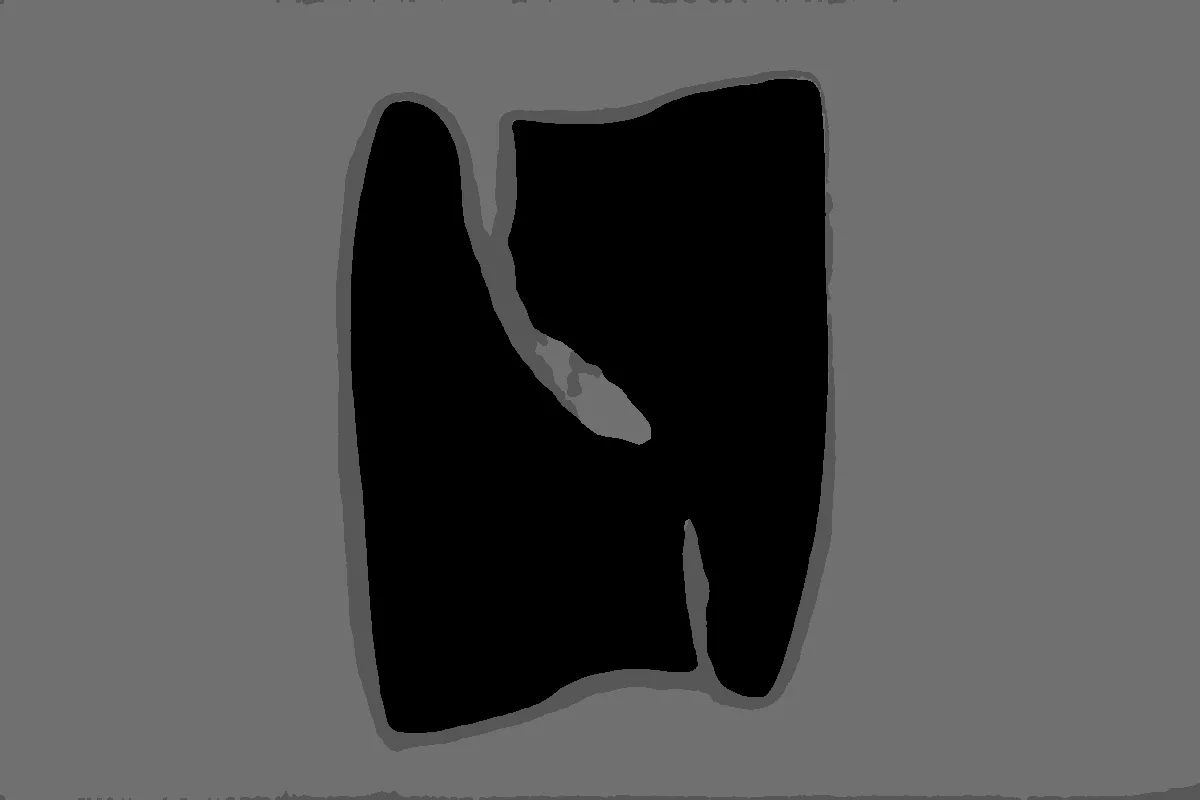
The segmentation is quite decent, especially with the edges smoothed, and the whole process takes approximately 8 seconds on an M1 MacBook Air. Apart from the longer-than-comfortable time taken, the edge detection could also be better. The example above has an extra strip to the left of the book, whereas the one below has a more obvious portrayal of this issue.


Even though the segmentation around the turtle's head and flippers are adequate, the keychain loop has been cropped out. This is where Apple's article about object segmentation comes to the rescue.
Act 3. Guided feathering.
Stay tuned to find out how I obtained the following result! (WIP, of course)
